Machine learning models are commonly used today in many applications to drive insights and to make predictions. However, many high performing models such as random forests and neural networks are black boxes and lose explainability where users are not able to fully understand the reasons behind a model's predictions! This becomes a problem since we don't know when to trust or not to trust a model?
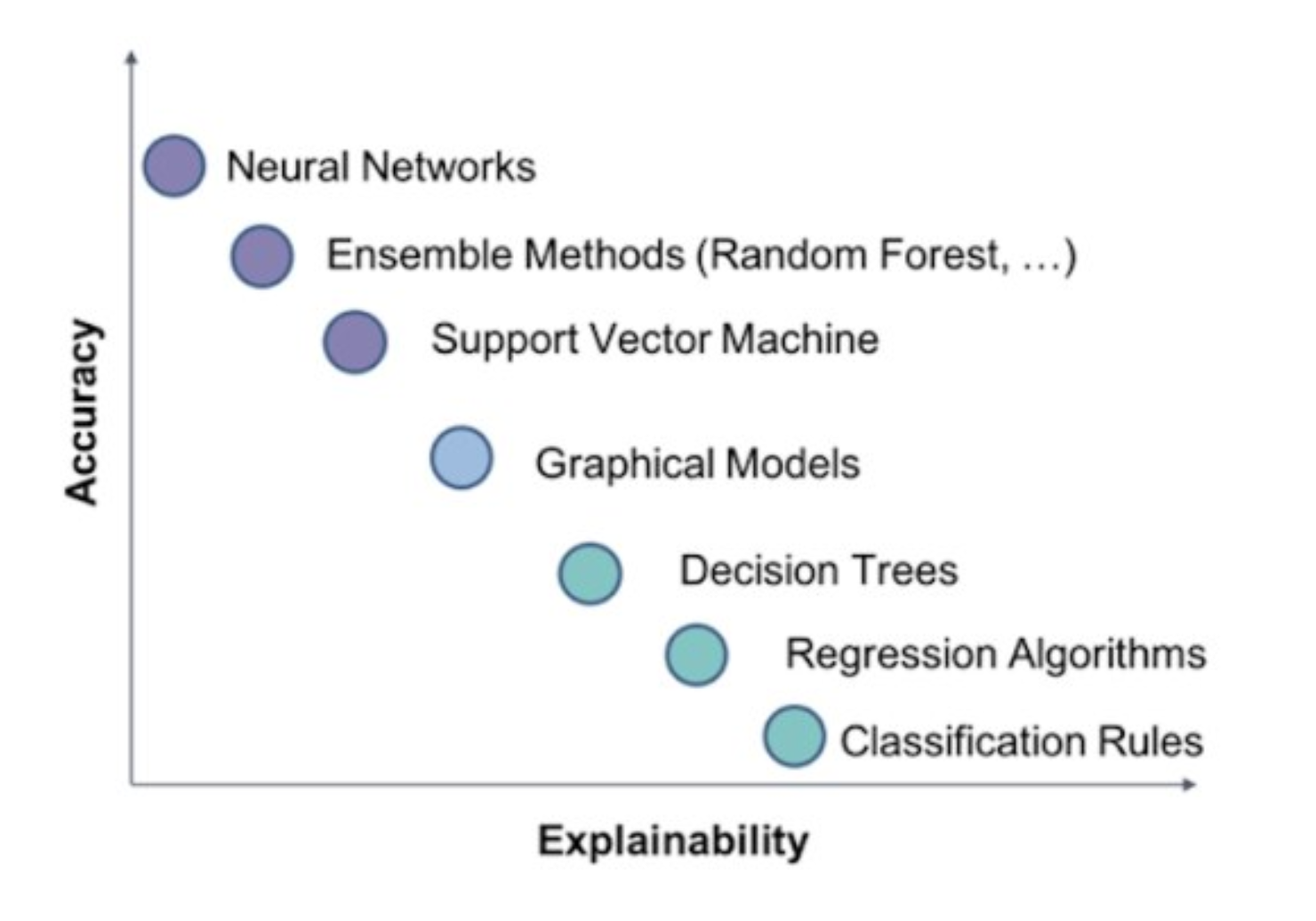
Having a model that scores great on evaluation metrics is not good enough. Understanding predictions and having it match our intuition can provide us confidence that the model is not biased. Being able to interpret predictions is particularly important when predictions are to be implemented for certain applications such as self-driving cars or for sensitive information such as an individual's health status or credit score.
This is where LIME (local interpretable model-agnostic explanations) can be used to explain individual predictions for text classifiers and images! Check out the open source package for more information and links to tutorials.
Here we'll go through a (rather silly) text classifier using random forests and see how LIME can be used to explain the predictions. A classifier will be trained to predict which of the following two subreddit topics a post belongs to based on its text content.
- r/Constipation
🚫💩 A place for people with constipation issues, where all questions related with the condition can be debated. - r/NoPoo
👨🦱 "No Shampoo" A place to discuss natural hair care and alternatives to shampoo.
Subreddit Classification
# pip install lime
Fetching Data
Posts were collected from the subreddits by accessing Reddit's API and saved in a 'data.csv' file. Check out this repository to see the code and how the data was scraped.
# import data
import pandas as pd
df = pd.read_csv('data.csv', index_col = 0)
# take a look at the dataframe
pd.set_option('display.max_colwidth', -1)
df.head(3)
| name | selftext | subreddit | |
|---|---|---|---|
| 0 | t3_a66615 | Hi everyone!\n\nIt seems that our little community has been growing for a while, so I've took the liberty of providing our space a more appealing look. Hope you enjoy it.\n\nRegarding the new rules, you can check them [here](https://www.reddit.com/r/Constipation/about/rules/) or in the sidebar. They are pretty simple, but your opinions and questions are welcome.\n\nLastly, do not forget to always check a health professional if you have a serious condition. | Constipation |
| 1 | t3_bnhb70 | Hi! Hoping y'all may be able to help me. I'm 25/M and I've never had constipation issues before. I get anxiety semi-easily so I'm hoping one of you friendly folks can help me ease my worries. <333\n\nBasically, I've only had small pebbles / small pencil-shaped BMs for around 8 or 9 days now. No sizable BMs. I was very dehydrated and eating horribly when this started (an anomaly for me) which almost certainly triggered it, so I've been drinking 3 liters of water and eating much much healthier every day since.\n\nI went to a GI doctor 4 days ago and he told me to take Miralax once daily and to supplement with Metamucil if I want, which I've been doing. It hasn't really helped as far as I can tell. I'm not in pain, just mild discomfort, but I'm a little worried and want to nip this in the bud. Today is day 8, and I took a full dose (30ml) of Milk of Magnesia this morning and it only resulted in a few small bursts of green powdery-looking diarrhea — which I sense may be the Metamucil fiber mixed with the green chlorophyll of all the vegetables I'm eating. Now I've just inserted a glycerin suppository 30 minutes ago but I'm not really feeling anything at all.\n\nI have a check-in with the GI doctor on Monday since he doesn't work weekends. Should I try and see an urgent care doctor before then? Is there something else I should try? | Constipation |
| 2 | t3_bnjy06 | I'm curious as to what I should do. I haven't been able to go for 2 days but when I go theres always a lot and I go to the bathroom daily. For me to go 1 day without I'd worrisome. Then, the discomfort set in. Now, I'm in bed and my leg is shaking trying to hold in the waste because it hurts much to bad to go. I know I need to drink more water and Im pretty sure the cause was what I had to eat. It hurts so bad and I've shamefully taken more pills than I should have. 2 different types of laxative and a stool softener. It still hurts too bad but for there to be as much as I suspect, I could use some form of immediate release. Any help is much appreciated and the sooner, the better. | Constipation |
df.tail(3)
| name | selftext | subreddit | |
|---|---|---|---|
| 6821 | t3_7wgpo6 | Hi everyone! New here and have a question after reading a bit here and there about WO.\n\nIt's been only a week since the last shampoo and my hairs are not that bad. A bit oily at the roots but nothing disgusting (I mostly keep my hairs in a bun with just a towel drying). The ends are dry but I want to see where it goes on a longer run. I saw that I'm suppose to use cold water to keep the sebum from going away and produce more and to close the pores. But, I just can't use cold water, even just for a minute. My brain won't allow it and I will probably be grumpy all day long. I know it is a caprice but you know, we all have some. So, will it just not work because of that or hot water is ok too? Thank you in advance!!! | NoPoo |
| 6822 | t3_7wavp8 | NaN | NoPoo |
| 6823 | t3_7vzh7b | NaN | NoPoo |
Cleaning and Pre-processing Text
Removing Blanks
We will first remove any NaN rows (in the column selftext)
df = df.dropna()
Train, Test, Split
Before doing any further processing to our dataframe, let's train test split!
from sklearn.model_selection import train_test_split
x = df['selftext']
y = df['subreddit'].map({'Constipation':0, 'NoPoo':1})
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size = 0.20, random_state = 42)
Tokenizing, Lower Case, Lemmatizing, Stop Words, HTML
The function text_to_words() below will extract highly important features from our textual data by converting a raw post to a "cleaned" string of words. The input is a single string (a raw post) and the output is a string (a preprocessed post).
The function will convert a single string (a raw post) by:
-
Removing any HTML (i.e. \n as can be seen from our preview of our df above)
-
Converting to lower case
-
Tokenizing the post into words, removing punctuation
-
Lemmatizing
- Lemmatizing is preferred over Stemming because stemming cuts off the end or the beginning of words. With this method, important parts of the words may sometimes be chopped off.
-
Removing stop words
from bs4 import BeautifulSoup
from nltk.tokenize import RegexpTokenizer
from nltk.corpus import stopwords
def text_to_words(selftext):
text = BeautifulSoup(selftext).get_text()
lower_case = text.lower()
retokenizer = RegexpTokenizer(r'[a-z]+')
word_tokens = retokenizer.tokenize(lower_case)
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
tokens_lem = [lemmatizer.lemmatize(i) for i in word_tokens]
stops = set(stopwords.words('english'))
meaningful_words = [w for w in tokens_lem if not w in stops]
return(" ".join(meaningful_words))
The function pre_process() below will call the text_to_words() function to pre-process every post in the data set.
def pre_process (X):
# prints out number of posts
num_text = X.size
clean_text = []
print(f'Number of posts: {num_text}\n')
print("Cleaning and parsing posts...")
for i in range(0, num_text):
# if the index is evenly divisible by 500, print a message
if((i+1) % 500 == 0):
print('Review %d of %d' % ( i+1, num_text))
clean_text.append(text_to_words(X.iloc[i]))
return clean_text
clean_X_train = pre_process(X_train)
print('\n')
clean_X_test = pre_process(X_test)
Number of posts: 4566
Cleaning and parsing posts...
Review 500 of 4566
Review 1000 of 4566
Review 1500 of 4566
Review 2000 of 4566
Review 2500 of 4566
Review 3000 of 4566
Review 3500 of 4566
Review 4000 of 4566
Review 4500 of 4566
Number of posts: 1142
Cleaning and parsing posts...
Review 500 of 1142
Review 1000 of 1142
# taking a look at pre-processed posts
clean_X_train[0:3]
['going low poo couple month usually alternate water co wash lush shampoo conditioner wash hair week really curly hair tried bicarb acv work first couple time hair feel weird lush shampoo ok use poo ha anyone used poo pulled marketing scheme btw conditioner work really well hair',
'rectum cannot take much poop cannot help involuntarily push',
'title say dealing constipation issue since wa kid use take mineral oil changed eating fiber food peanut peanut butter veggie drinking water oatmeal along eating fiber gummies x b nowadays notice poop maybe day row poop whole another week tummy hurt said hurt sit stand walk bend etc x b go poop poop small size normal worried tummy hurting like constipated']
clean_X_test[0:3]
['stopped eating carbs wa major rice bread pasta oat milk eater cut eat plenty protein nut plant altered amount water drink constipation gone still poop irregularly least pain buttery soft blood new diet rock done',
'hi everyone started nopoo last summer used shampoo month shower daily usually wash hair hot water degree celsius think remove oily buildup hair feel fine greasy think look better read post saying wash cold water experience think better year old male regular long anything hair',
'like many member community kind stumbled upon nopoo one day reading decided give shot initially bought shampoo bar planned use greasy transition phase ended using couple time made hair feel exactly would use head shoulder used daily discovering sub probably guess wa using h ditched shampoo altogether wa hoping nopoo would solve dandruff issue year later thrilled texture life hair ironically one thing wa hoping would wa hoping could get input changing routine try curb issue thing may helped wa one time gf rubbed scalp coconut oil seem remember day improvement following perfectly honest never made connection typing lol advice greatly appreciated would like stick closely possible water natural better willing compromise miracle product hope day going well thank taking time read post']
Vectorizing
TfidfVectorizer() weights down the common words occuring in almost all the documents and give more importance to the words that appear in a subset of documents. TF-IDF works by penalising these common words by assigning them lower weights while giving importance to some rare words in a particular document.
from sklearn.feature_extraction.text import TfidfVectorizer
tvec = TfidfVectorizer()
X_train_vectors = tvec.fit_transform(clean_X_train)
X_test_vectors = tvec.transform(clean_X_test)
Training a Classifier
Our data is finally ready to fit into our model 🙂. We will be using Random Forests here. With a multitude of decision trees, imagine trying to understand how predictions are being made within and between each tree!
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(n_estimators = 100)
model.fit(X_train_vectors, y_train)
RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini',
max_depth=None, max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=100,
n_jobs=None, oob_score=False, random_state=None,
verbose=0, warm_start=False)
model.score(X_train_vectors, y_train)
1.0
model.score(X_test_vectors, y_test)
1.0
As you can see here, the accuracy is 100%. Suspicious? Without being able to understand how the model is making it's predictions, how can we trust using the model?
Explaining Predictions using LIME
As guided by the package's tutorials, we'll take a look at two individual predictions.
from lime import lime_text
from sklearn.pipeline import make_pipeline
c = make_pipeline(tvec, model)
Example #1
For the following text, the model is predicting that it belongs to the Constipation subreddit with 100% probability.
# raw post content
X_test.iloc[10]
'On Sunday I went to the doctor, had abdominal xrays and it was determined I am extremely constipated. Did blood, urine, and ekg tests too with no real read flags. I’ve been using some laxatives and have managed to pass a couple decent stools. I’m worried though because my urges just aren’t there, even with the laxatives and I’m worried it’s an impaction but how do you know for sure. Is it something one feels more towards the anus? My main area of concern is in my pelvis right now. Is it possible stuff that was up higher that worked down and is now impacted. Will this ever end, I am an active healthy eating dude for the most part. Why me?'
# 'cleaned' post
clean_X_test[10]
'sunday went doctor abdominal xrays wa determined extremely constipated blood urine ekg test real read flag using laxative managed pas couple decent stool worried though urge even laxative worried impaction know sure something one feel towards anus main area concern pelvis right possible stuff wa higher worked impacted ever end active healthy eating dude part'
c.predict_proba([clean_X_test[10]])
array([[1., 0.]])
from lime.lime_text import LimeTextExplainer
class_names = ['Constipation', 'NoPoo']
explainer = LimeTextExplainer(class_names = class_names)
We now generate an explanation with at most 6 features for an arbitrary document (idx = 10 in this case).
def generate_explanation(idx):
exp = explainer.explain_instance(clean_X_test[idx], c.predict_proba, num_features = 6)
print('Document id: %d' % idx)
print('Probability (0 = Constipation, 1 = NoPoo) =', c.predict_proba([clean_X_test[idx]])[0,1])
print('True class: %s' % y_test.iloc[idx])
return exp
import warnings
warnings.simplefilter(action = 'ignore', category = FutureWarning)
idx = 10
exp = generate_explanation(idx)
Document id: 10
Probability (0 = Constipation, 1 = NoPoo) = 0.0
True class: 0
Explanation as a List of Weighted Features
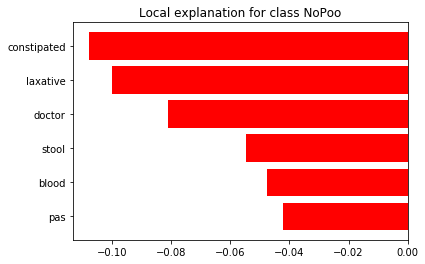
exp.as_list()
[('constipated', -0.107871868345285),
('laxative', -0.09991877751121268),
('doctor', -0.08106818266053437),
('stool', -0.05479540347035812),
('blood', -0.04762371873105442),
('pas', -0.04199893038075257)]
# 'cleaned' post
clean_X_test[10]
'sunday went doctor abdominal xrays wa determined extremely constipated blood urine ekg test real read flag using laxative managed pas couple decent stool worried though urge even laxative worried impaction know sure something one feel towards anus main area concern pelvis right possible stuff wa higher worked impacted ever end active healthy eating dude part'
... as a Visual Plot
%matplotlib inline
fig = exp.as_pyplot_figure()
... with Another Type of Visual
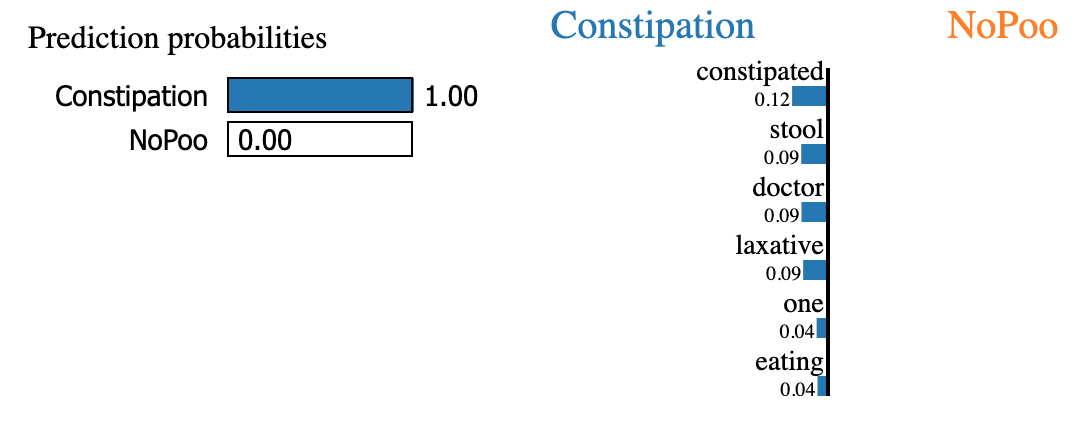
exp.show_in_notebook(text = False)
<script>
var top_div = d3.select('#top_divCRX9UCO3TV1TT73').classed('lime top_div', true);
var pp_div = top_div.append('div')
.classed('lime predict_proba', true);
var pp_svg = pp_div.append('svg').style('width', '100%');
var pp = new lime.PredictProba(pp_svg, ["Constipation", "NoPoo"], [1.0, 0.0]);
var exp_div;
var exp = new lime.Explanation(["Constipation", "NoPoo"]);
exp_div = top_div.append('div').classed('lime explanation', true);
exp.show([["constipated", -0.107871868345285], ["laxative", -0.09991877751121268], ["doctor", -0.08106818266053437], ["stool", -0.05479540347035812], ["blood", -0.04762371873105442], ["pas", -0.04199893038075257]], 1, exp_div);
var raw_div = top_div.append('div');
</script>
</body></html>
... with Words from the Explanation Highlighted in Original Document
exp.show_in_notebook(text = True)
<script>
var top_div = d3.select('#top_divGC5KZ0TMVTBMPF3').classed('lime top_div', true);
var pp_div = top_div.append('div')
.classed('lime predict_proba', true);
var pp_svg = pp_div.append('svg').style('width', '100%');
var pp = new lime.PredictProba(pp_svg, ["Constipation", "NoPoo"], [1.0, 0.0]);
var exp_div;
var exp = new lime.Explanation(["Constipation", "NoPoo"]);
exp_div = top_div.append('div').classed('lime explanation', true);
exp.show([["constipated", -0.107871868345285], ["laxative", -0.09991877751121268], ["doctor", -0.08106818266053437], ["stool", -0.05479540347035812], ["blood", -0.04762371873105442], ["pas", -0.04199893038075257]], 1, exp_div);
var raw_div = top_div.append('div');
exp.show_raw_text([["constipated", 59, -0.107871868345285], ["laxative", 113, -0.09991877751121268], ["laxative", 179, -0.09991877751121268], ["doctor", 12, -0.08106818266053437], ["stool", 148, -0.05479540347035812], ["blood", 71, -0.04762371873105442], ["pas", 130, -0.04199893038075257]], 1, "sunday went doctor abdominal xrays wa determined extremely constipated blood urine ekg test real read flag using laxative managed pas couple decent stool worried though urge even laxative worried impaction know sure something one feel towards anus main area concern pelvis right possible stuff wa higher worked impacted ever end active healthy eating dude part", raw_div, true);
</script>
</body></html>

The top words for this example that led the model to predict it to be associated with Constipation rather than NoPoo (no shampoo) are constipated, laxative, doctor stool, blood, and pas. Makes sense to me!
Example #2
Let's take a look at another example.
X_test.iloc[20]
"Title says it all. I'm a male who knows absolutely *nothing* about this stuff but has relatively long hair. I'd like to fix this whole thing where I have shit hair one out of every three days.\n\n&#x200B;\n\nAlso, does this work if you use hairspray?"
clean_X_test[20]
'title say male know absolutely nothing stuff ha relatively long hair like fix whole thing shit hair one every three day x b also doe work use hairspray'
idx = 20
exp = generate_explanation(idx)
Document id: 20
Probability (0 = Constipation, 1 = NoPoo) = 0.96
True class: 1
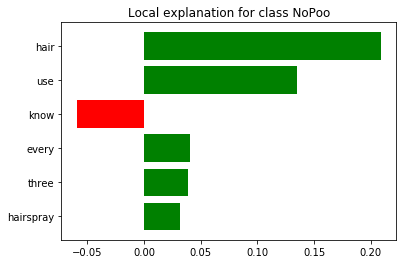
For this example, the model is predicting that it belongs to the NoPoo subreddit with 96% probability. My intuition is that there are enough words in the post content to indicate that it is talking about no shampoo but the word SH*T throws it off a little. Let's see if this aligns with how the model made its predictions.
fig = exp.as_pyplot_figure()
exp.show_in_notebook(text = True)
<script>
var top_div = d3.select('#top_div5JBCC27WH8BKSW6').classed('lime top_div', true);
var pp_div = top_div.append('div')
.classed('lime predict_proba', true);
var pp_svg = pp_div.append('svg').style('width', '100%');
var pp = new lime.PredictProba(pp_svg, ["Constipation", "NoPoo"], [0.04, 0.96]);
var exp_div;
var exp = new lime.Explanation(["Constipation", "NoPoo"]);
exp_div = top_div.append('div').classed('lime explanation', true);
exp.show([["hair", 0.20898418481685452], ["use", 0.1349930151287181], ["know", -0.05952452601602141], ["every", 0.04063578208234653], ["three", 0.03853294444880628], ["hairspray", 0.03205702249970073]], 1, exp_div);
var raw_div = top_div.append('div');
exp.show_raw_text([["hair", 64, 0.20898418481685452], ["hair", 95, 0.20898418481685452], ["use", 138, 0.1349930151287181], ["know", 15, -0.05952452601602141], ["every", 104, 0.04063578208234653], ["three", 110, 0.03853294444880628], ["hairspray", 142, 0.03205702249970073]], 1, "title say male know absolutely nothing stuff ha relatively long hair like fix whole thing shit hair one every three day x b also doe work use hairspray", raw_div, true);
</script>
</body></html>

Conclusion
The word SH*T did not show up in the 6 top features for the model's predictions! Rather the word 'know' seemed to associate more with Constipation and 'every' to NoPoo for this particular post, which both seem fairly neutral words to me. Should these words even be used as predictors? Is the model right, wrong, or biased? Is it discovering something we humans don't see? That is why it is so important to be able to have some interpretability to a model's predictions even if it has a high accuracy score so that we can decide to trust it or not.
Caveat: Issues with LIME
Since LIME is used to explain individual predictions, it may not provide insight into how the model predicts on new input data
For example here, the model associates "not" and "bad" to a positive post while for another piece of text it associates the same word "not" and "good" to a negative post.

To end off, an interesting Tedx Talk I watched lately talks about how small and insignificant words (to humans) like function and pronouns (e.g. I, the, and, me, us) were discovered to be better predictors for who people are, their power status, their emotional state, etc. than content/topic words (what people are writing about, nouns, verbs). If you have some time, I'd recommend watching it.
The Secret Life of Pronouns: James Pennebaker at TEDxAustin
I don't know what kind of models were used in James's discoveries, whether black box or not, but it shows the power of machine learning and computer power. Being able to better interpret a model's predictions allows end-users to gain insights and bring it back to the real world.